新浪科技讯 4 月 22 日下午消息,蚂蚁百灵正式推出 Ling-2.6-flash —— 一款总参数量 104B、激活参数 7.4B 的 Instruct 模型,主打“Token 效率”。
Ling-2.6-flash 沿用了 Ling 2.5 的混合线性架构设计,在 4 卡 H20 条件下推理速度最快可达到 340 tokens/s,Prefill 吞吐达到 Nemotron-3-Super 的 2.2 倍。
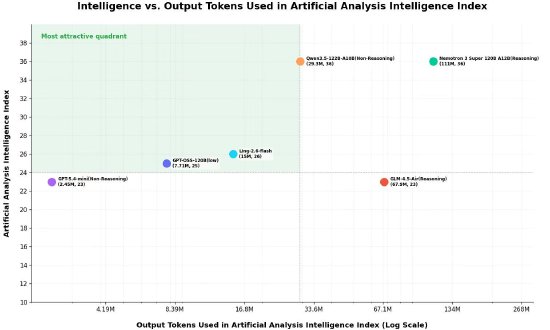
从 Token 消耗来看,Ling-2.6-flash 的智效比显著提升。在 Artificial Analysis 完整测评中,Ling-2.6-flash 总消耗为 15M tokens,而 Nemotron-3-Super 等模型达到或超过 110M tokens。
另外,Ling-2.6-flash 面向 Agent 场景进行了定向增强,模型在 BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench 等Agent 相关基准上达到同尺寸 SOTA 水平。
元股证券
API 定价方面,Ling-2.6-flash 输入每百万tokens定价 0.1 美元,输出 0.3 美元。

目前,Ling-2.6-flash 的 API 已正式向用户开放,并提供为期一周的限时免费试用。用户可以通过OpenRouter 、百灵大模型 tbox 获取对应服务。
元股证券:ygzq.hk
据了解,该模型后续将通过蚂蚁数科发布商业版本LingDT,服务全球开发者及中小企业。

海量资讯、精准解读,尽在新浪财经APP
责任编辑:王翔 证券开户流程查询入口
元股证券中心-在线业务大厅提示:本文来自互联网,不代表本网站观点。


